







LeanFocus 2.0
THE STORY BEHIND THE CODE: A DEEP DIVE
- Summary with focus on technical aspects
- App description
- Technical details
- Diagrams
- Technology and services used
SHOWCASING THE APP
Summary with focus on technical aspects
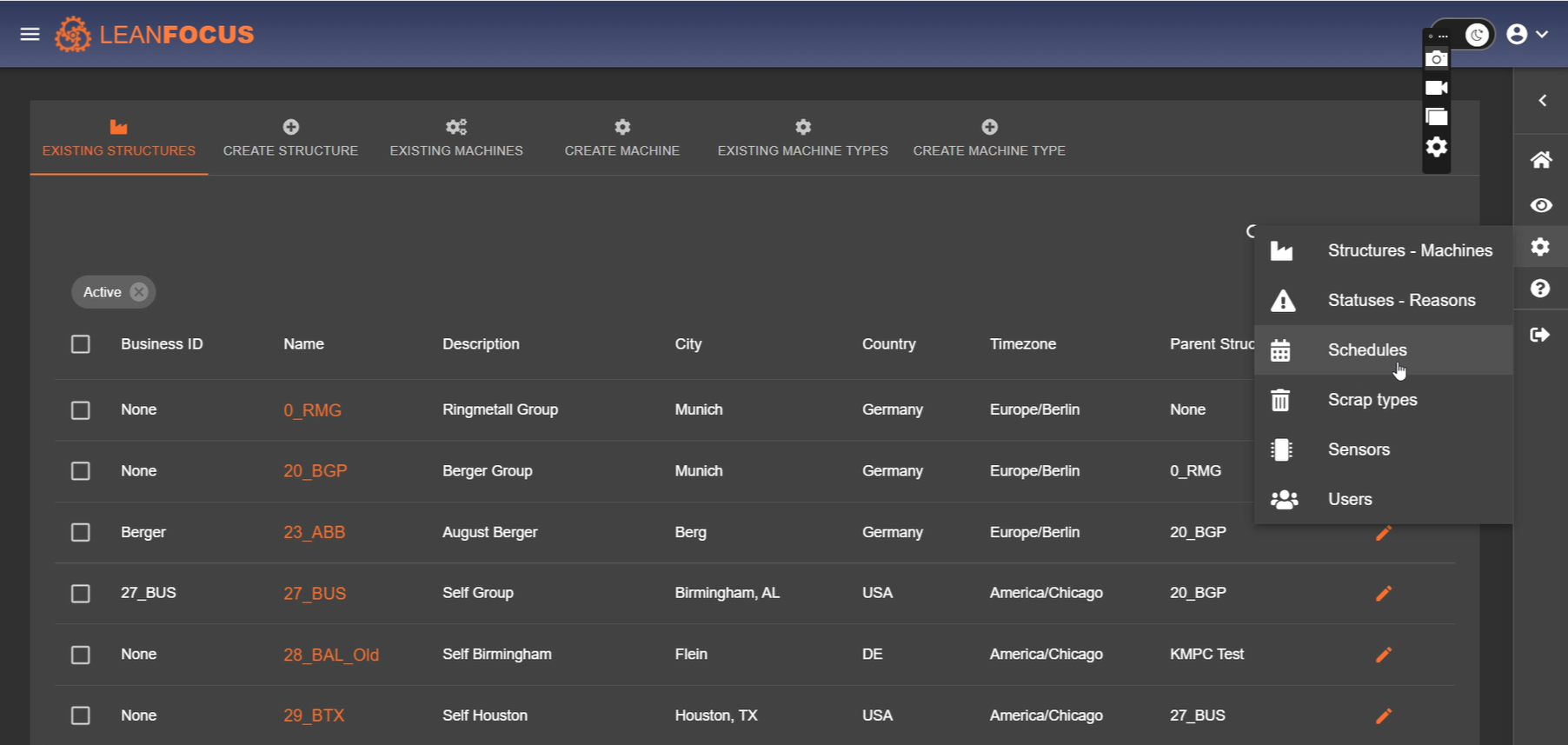
As the lead developer, I spearheaded the development of LeanFocus 2.0, an enterprise-level solution conceived to enhance the efficiency and real-time data tracking of hundreds of machines across multiple factories worldwide. The process of developing LeanFocus 2.0 was not without its challenges. Chief among them was the complex journey to a mutual understanding of terminology, a crucial step that became one of the crux moves throughout the development. This understanding was essential in aligning the project's objectives with the operational realities of factories, thereby ensuring that the app met the nuanced needs of its users. Additionally, designing the user experience (UX) presented its own set of challenges, especially in how real-time data needed to be effectively and intuitively presented on the Andon board. The goal was to ensure that the vast amount of real-time information was not only accessible but also actionable for users at any given moment.
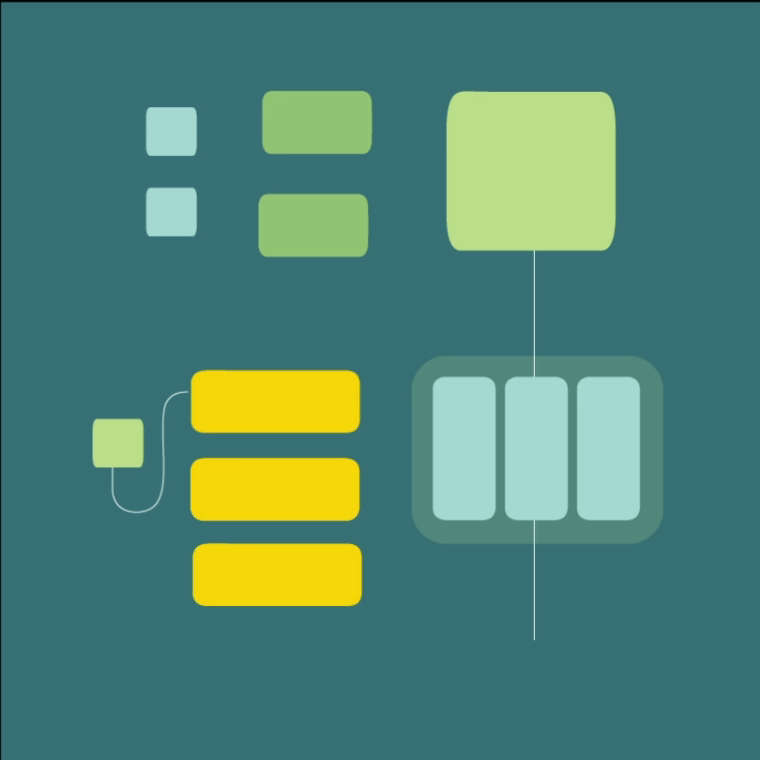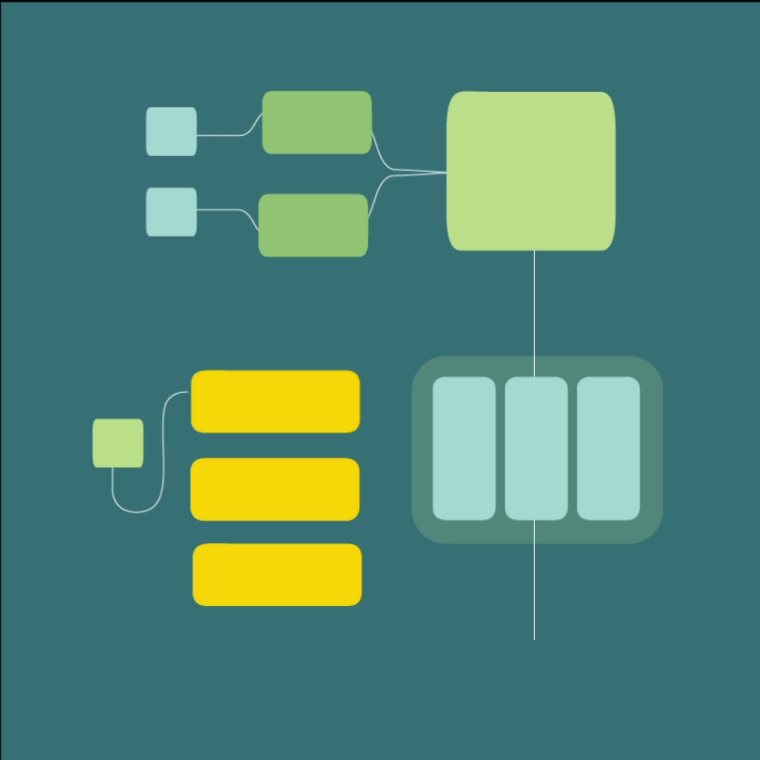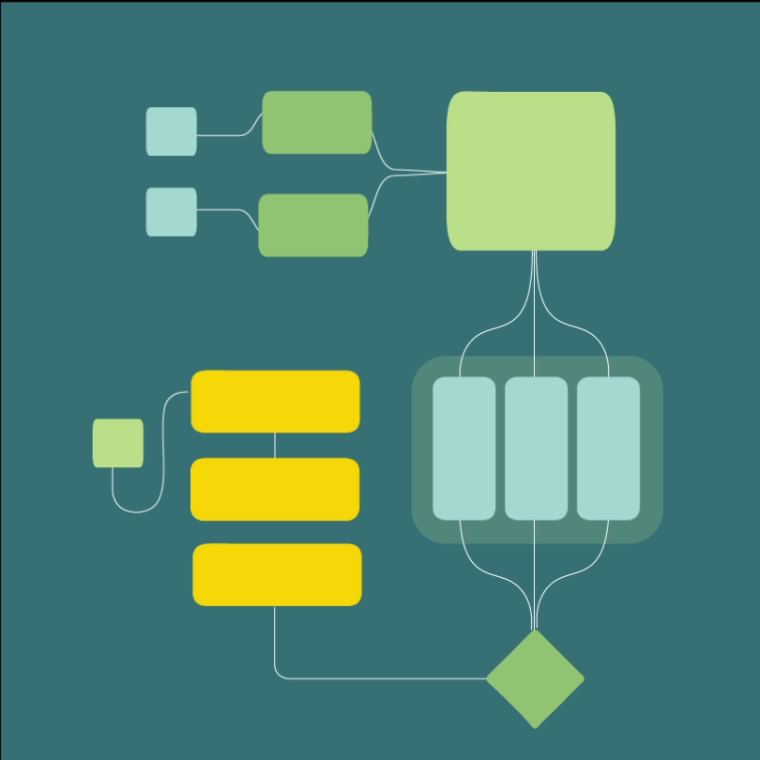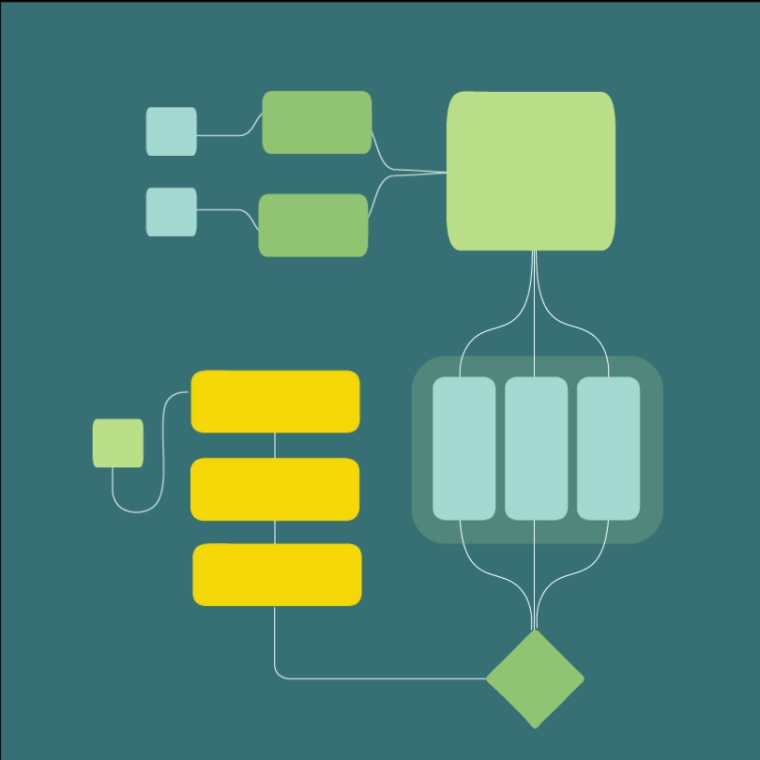
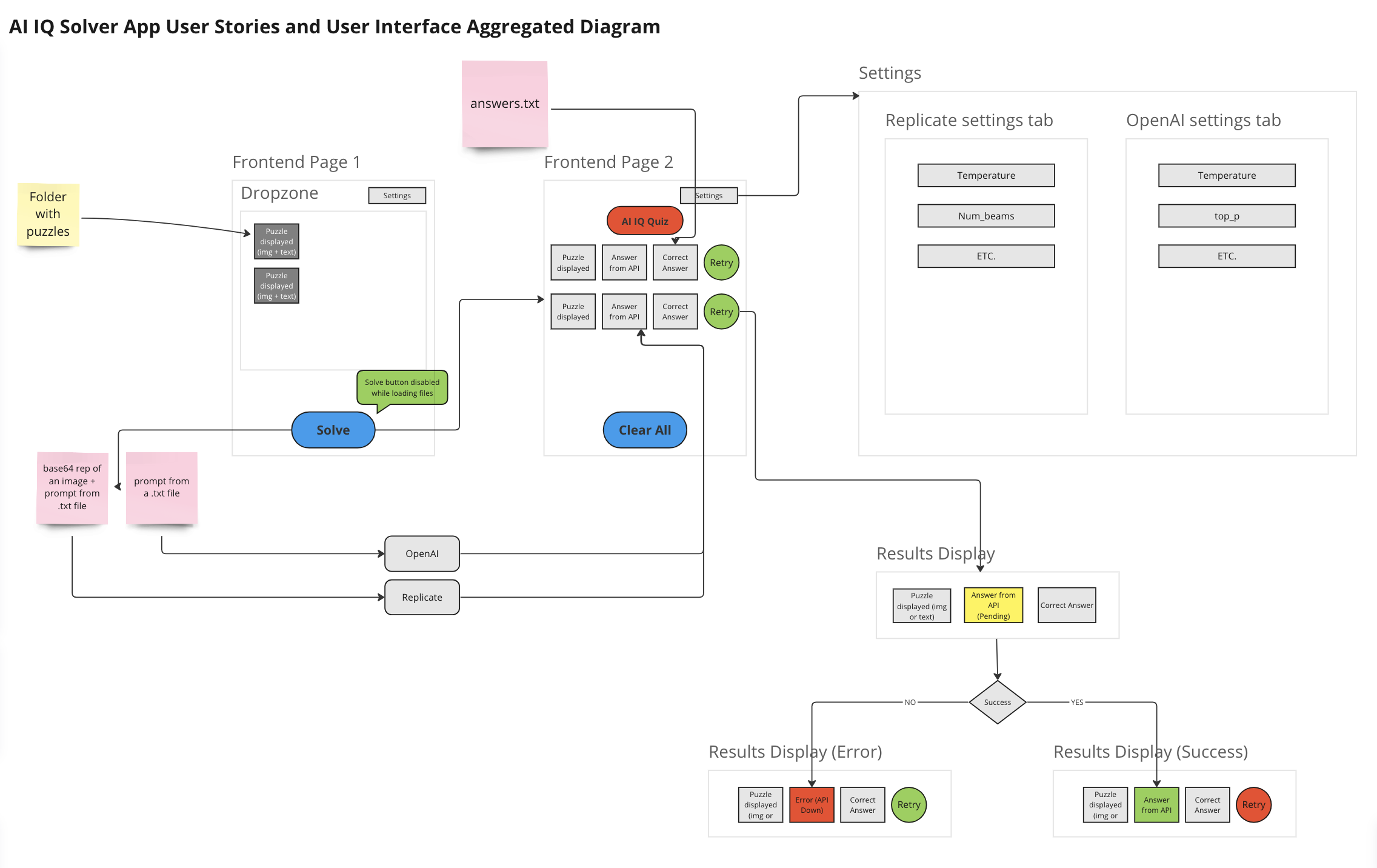
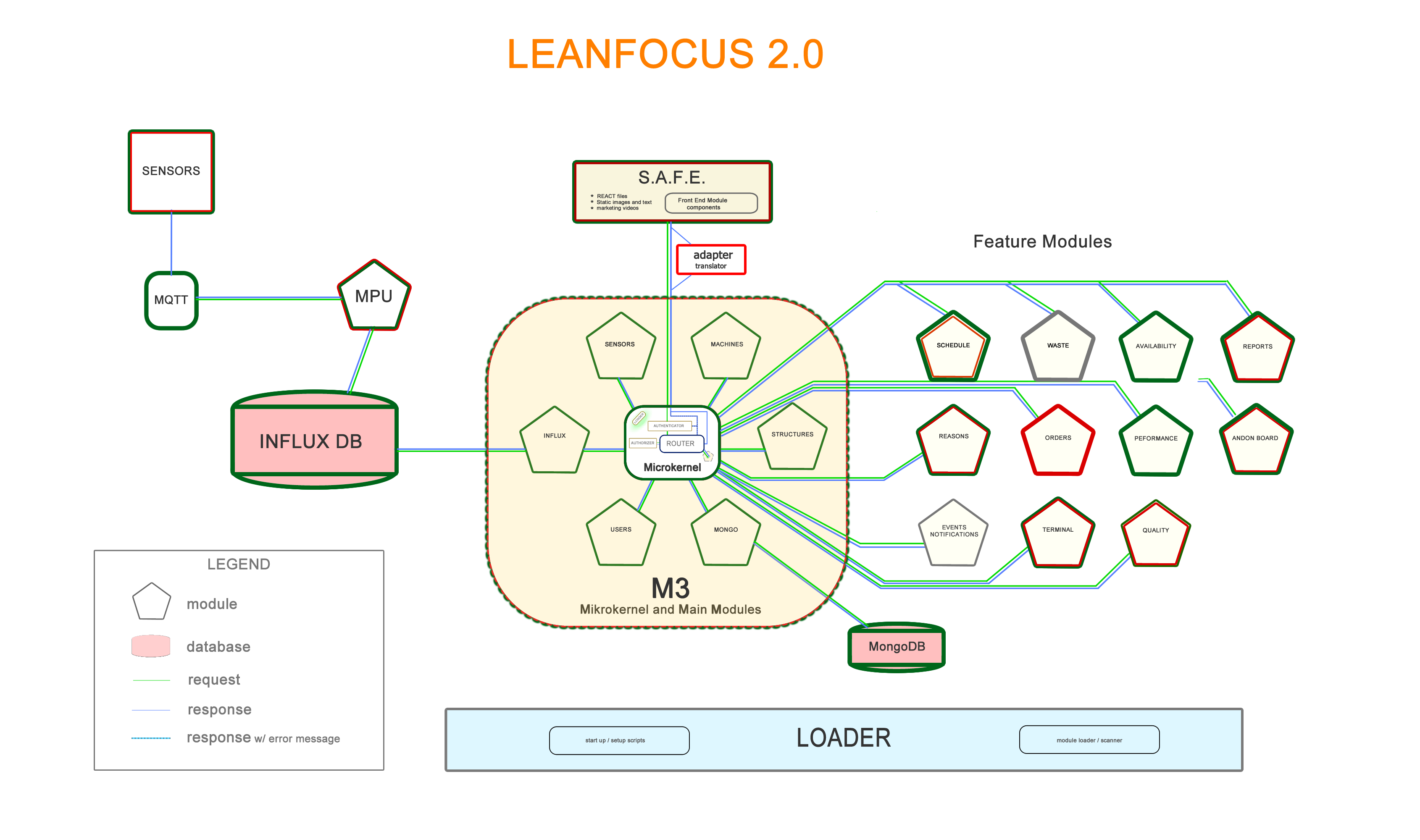
Embracing a microkernel architecture from the outset allowed us to ensure flexibility and the seamless integration of different data sources and functions. The backend, written in the Express Node.js web application framework, incorporates modern databases such as MongoDB for general data storage and InfluxDB for time-series data, crucial for real-time monitoring. Moreover, a complex custom user roles system was architected to cater to various stakeholders' needs, ensuring each user experiences a tailored interface and functionality that aligns seamlessly with their operational prerogatives.
MQTT was utilized for reliable sensor data connectivity, underpinning the app's real-time monitoring capabilities. This technology choice, alongside the intricate efforts in terminology and UX design, has resulted in a robust platform that not only meets the immediate operational needs but also adapts to the dynamic requirements of global factories.
App description
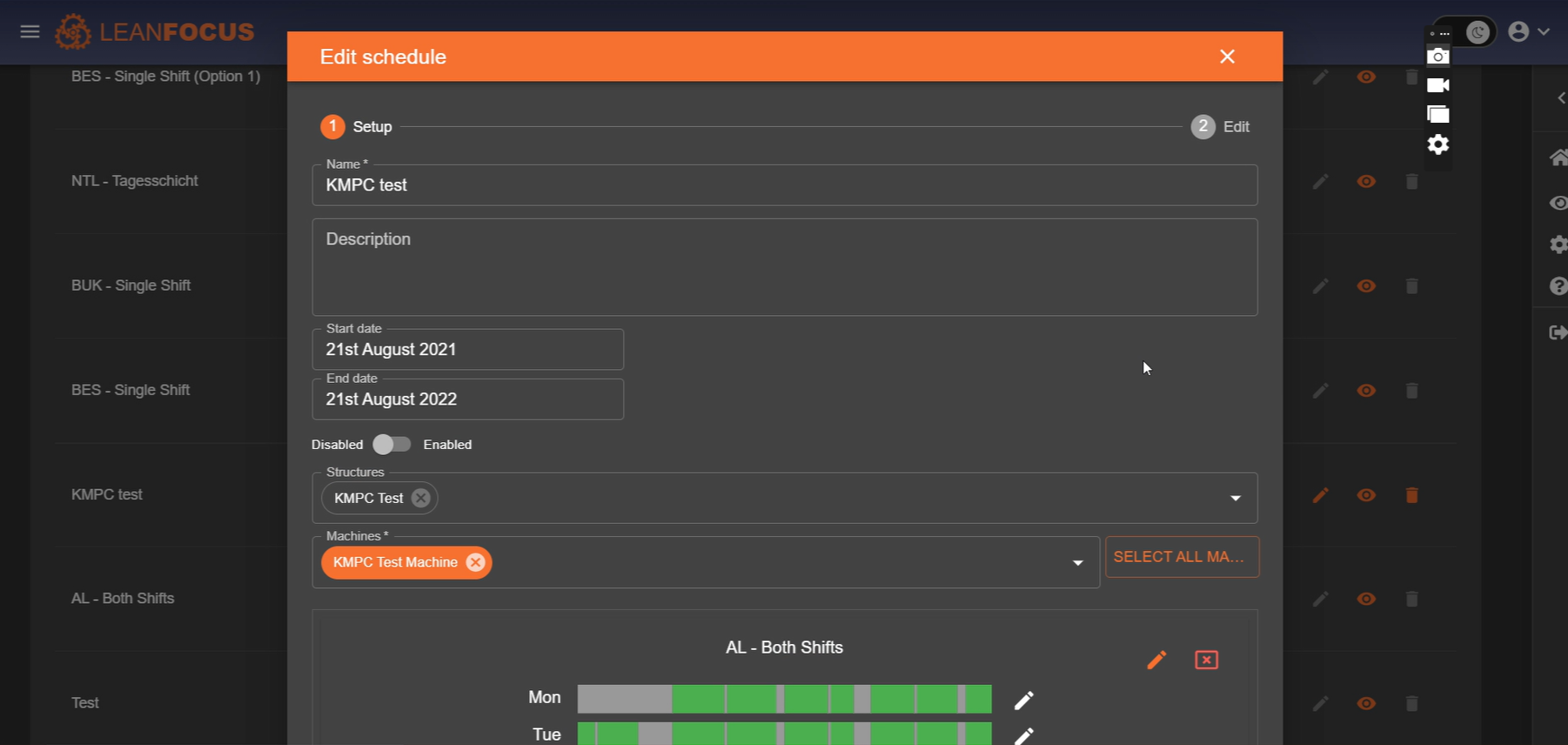
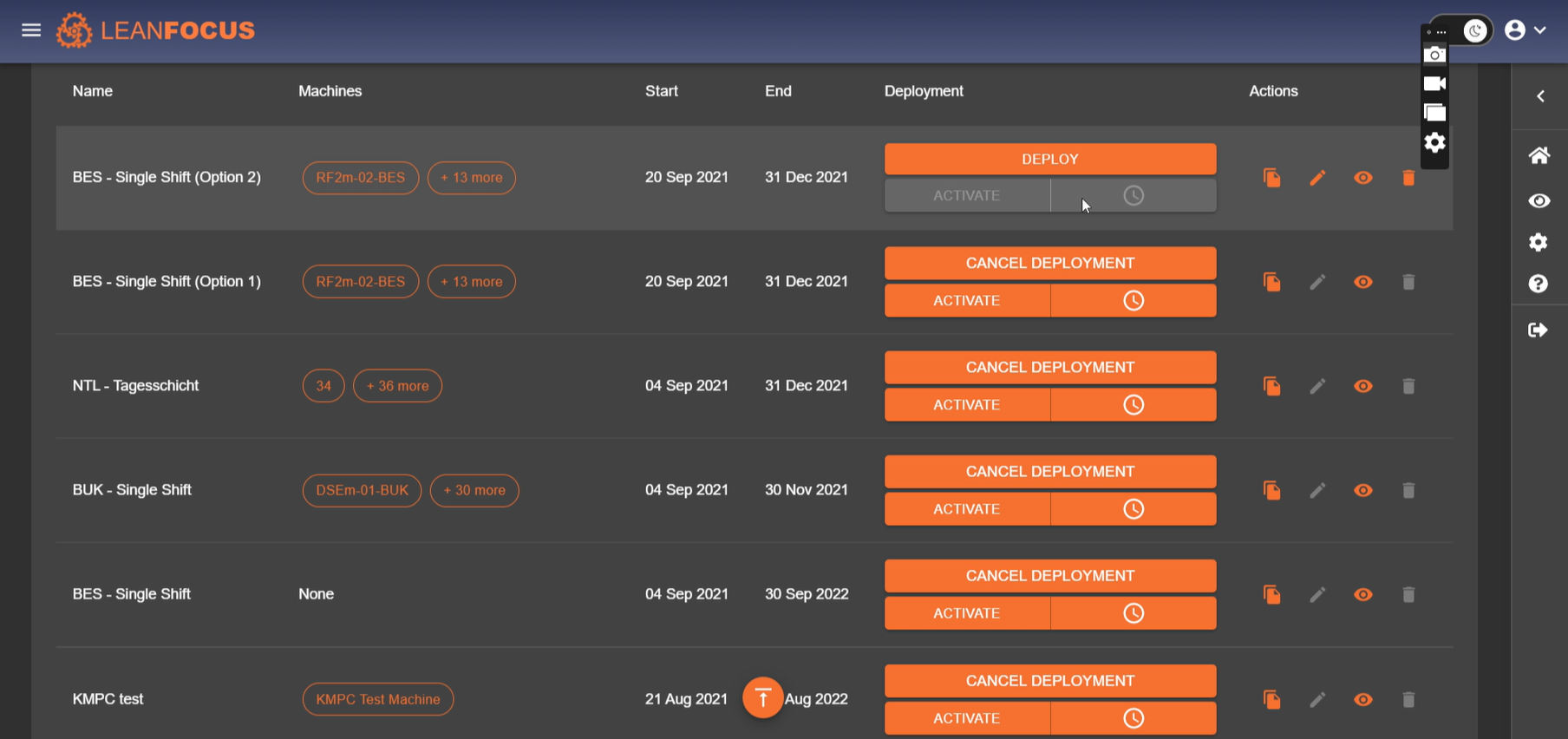
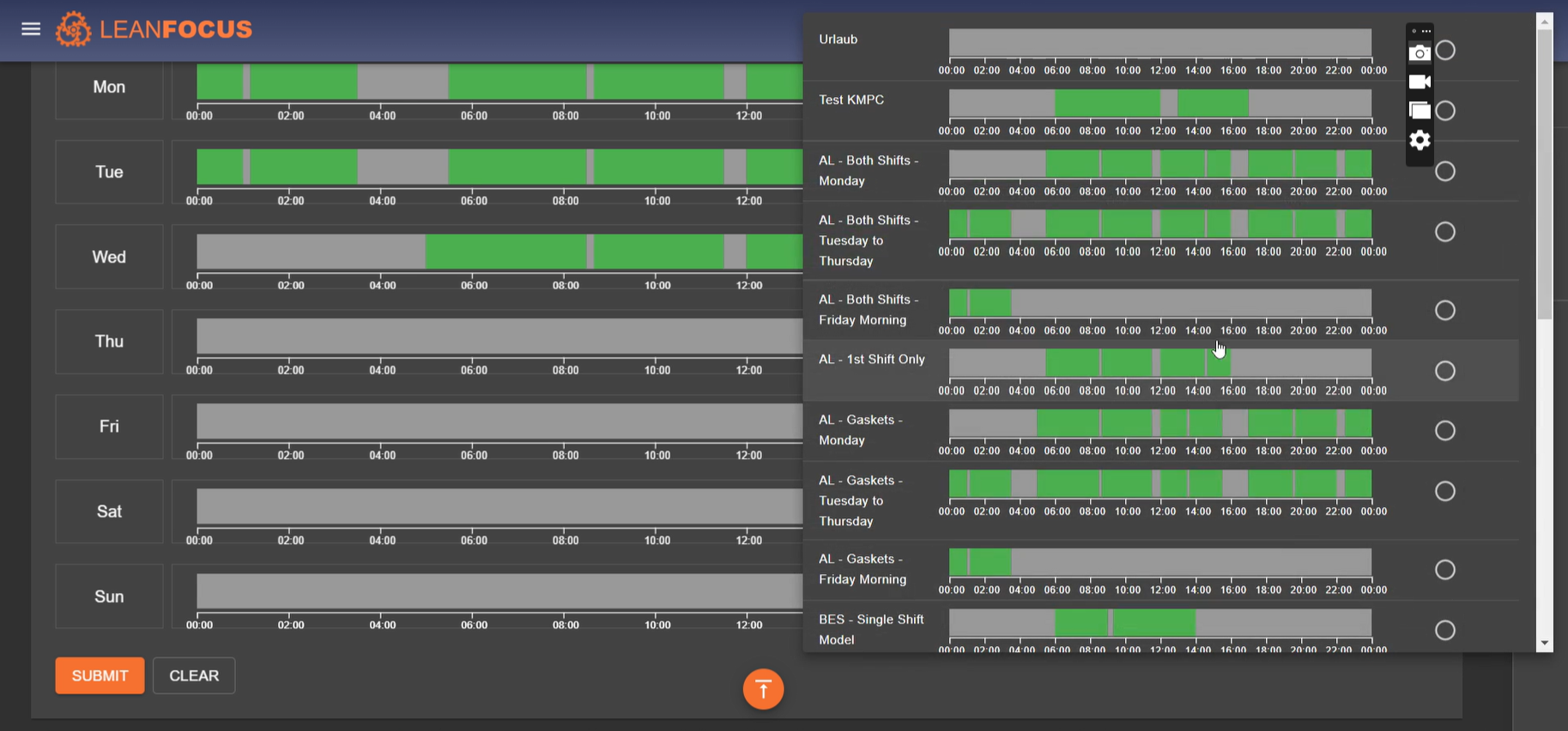
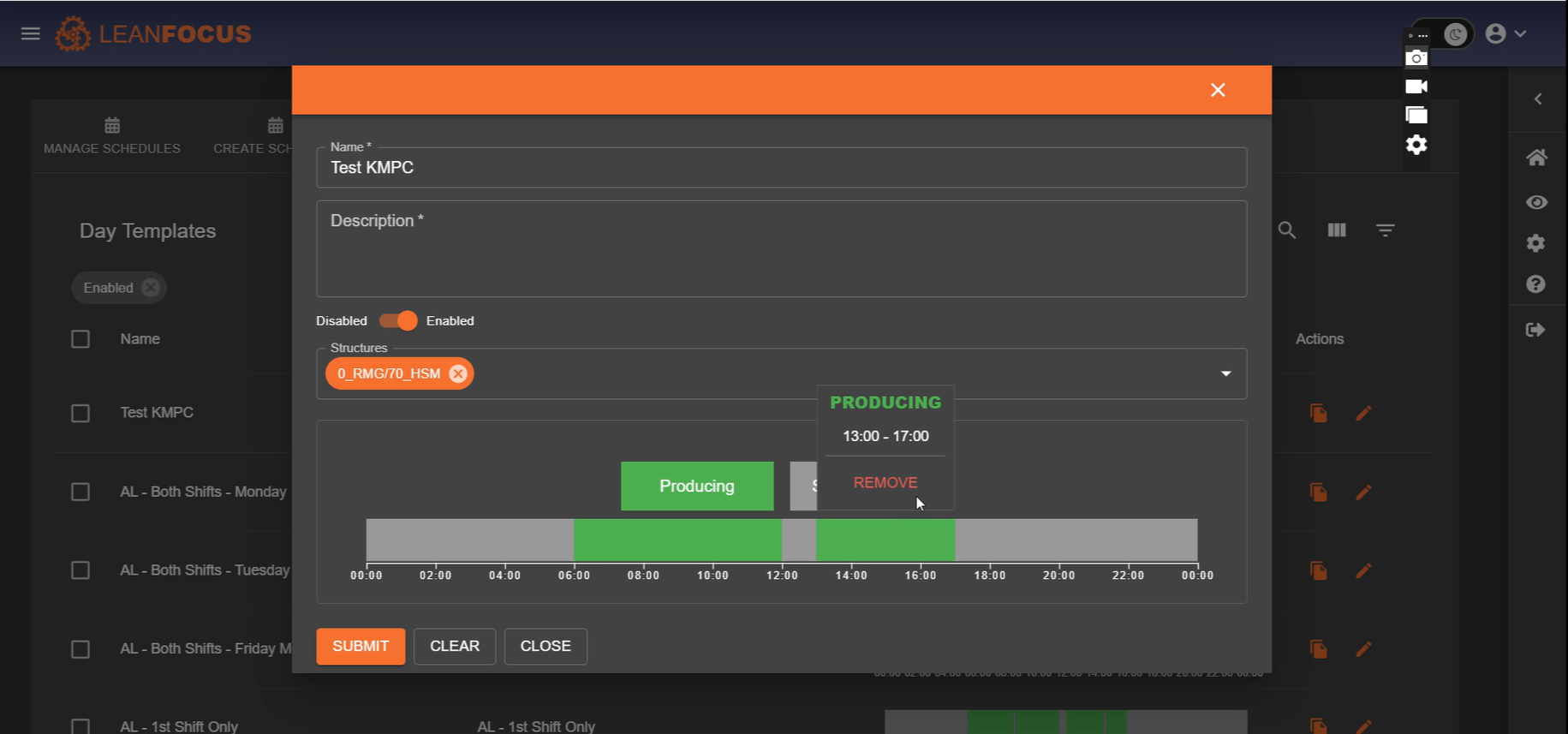
LeanFocus 2.0 streamlines the monitoring and management of factory operations by offering comprehensive tracking of machinery efficiency, real-time data analysis, and intuitive operational scheduling. At its core, the app is designed to improve overall equipment effectiveness (OEE) through detailed insights into machine availability, performance, quality ratings, and scheduled versus unscheduled downtimes. It includes a master navigation system for locating factories globally, managing orders, and facilitating the seamless interaction between machine operators and factory management. The intuitive Andon board display, both for comprehensive overviews and mobile-optimized availability checks, enhances the decision-making process by rendering complex data into easily interpretable visuals. The terminal functionality further ties into the hands-on aspects of production, allowing operators to input data regarding stoppages, quality, and order progress directly adjacent to their machines.
Technical details
LeanFocus 2.0 is written as React frontend and Express (Node.js web development framework) backend. It’s backbone is a microkernel architecture, chosen for its robustness in supporting the distributed nature of factory operations and for facilitating agile development and deployment practices. This design choice was paramount in achieving a configurable system that could adapt to various operational scales and requirements without compromising performance or security. MongoDB and InfluxDB were selected for their scalability and their aptitude in handling complex queries and large datasets effectively, critical factors given the app's data-intensive operations. MQTT protocol was implemented for its reliable message delivery, allowing for fault-tolerant communication between the vast array of machine sensors and the central system. The software architecture was meticulously planned to include a microkernel, essential main modules, and a S.A.F.E. (Stand Alone Front End), with an additional adapter for third-party API integrations to ensure comprehensive functionality and user experience. A sophisticated, custom user roles system was developed to provide targeted access and features based on user responsibilities and needs, enhancing both security and usability.
Diagrams
Technology and services used
- React
- Express
- MongoDB
- InfluxDB
- AWS